- De l’intelligence artificielle au deep learning
- Perceptron ou neurone formel
- Apprentissage d’un réseau de neurones

De l’intelligence artificielle au deep learning
L’apprentissage machine (ou machine learning) est l’une des méthodes relevant de l’intelligence artificielle. Au sein de cette famille, l’apprentissage profond (ou deep learning) est devenu prédominant et représente bien le modèle connexionniste. Il repose sur l’utilisation de réseaux de neurones artificiels. Ce billet se limitera à la description de la structure et de l’optimisation d’un tel réseau.
Perceptron ou neurone formel
Imaginé par Warren McCulloch et Pitts en 1943 puis amélioré par Frank Rosenblatt en 1958, le neurone artificiel élémentaire (ou perceptron) est un outil mathématique qui fait correspondre des entrées à des sorties au moyen d’une somme pondérée ∑, à laquelle on ajoute un terme de biais, qui est passé en argument à une fonction Φ, dite fonction d’activation. Celle-ci peut être une sigmoïde ou très souvent la fonction Unité Linéaire Rectifiée (ReLU). Elle sert à introduire de la non-linéarité dans le modèle. Historiquement, le perceptron a été utilisé dans des problèmes de classification.
Apprentissage d’un réseau de neurones
Vers la fin des années 80, les chercheurs ont réalisé que pour traiter des problèmes plus complexes, plusieurs neurones artificiels devaient être complètement connectés et organisés en couches. On distingue les couches d’entrée (x) et de sortie (y), et les couches cachées intermédiaires.
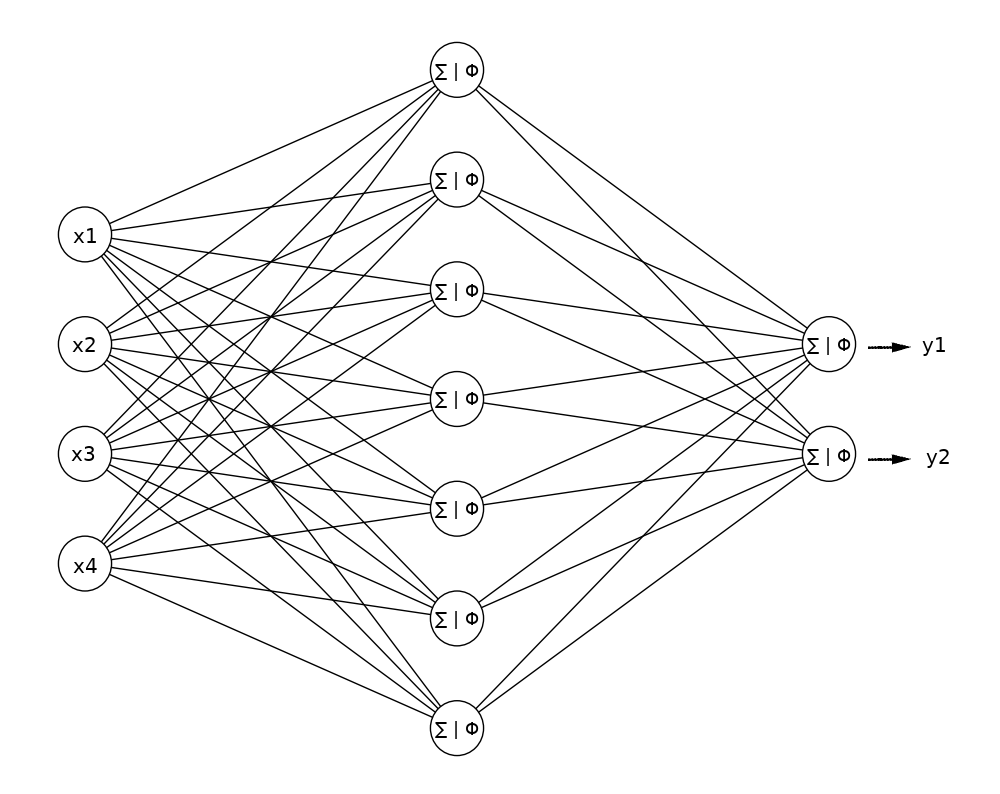
L’entraînement de ce réseau de neurones sur un jeu de données consiste à optimiser la totalité des poids et biais de façon à obtenir la meilleure prédiction possible. Ainsi, à chaque cycle d’apprentissage, une mesure de l’erreur entre les valeurs observées et prédites (loss function) moyennée sur toutes les observations est faite, et le réseau est mis à jour en minimisant cette erreur moyenne par descente de gradients. Pour un réseau à plusieurs couches, cette méthode fut rendue possible en 1986 grâce à un mécanisme de rétro-propagation (ou back propagation), partant de la couche de sortie pour retourner vers la couche d’entrée (en appliquant le théorème de dérivation des fonctions composées). En pratique, la descente de gradient est réalisée en opérant sur des sous-ensembles des observations (mini-batchs), dont la somme forme un epoch. La convergence par itérations nécessitera donc plusieurs epochs.
Prenons l’exemple d’une série d’observations dotées de 600 caractéristiques conduisant à deux prédictions par observation. Si le réseau est constitué de trois couches cachées de 250 neurones chacune, en n’oubliant pas de tenir compte des biais, on obtiendra 150250 paramètres pour la première couche, 62750 pour la seconde, 62750 pour la troisième, 502 pour la couche de sortie, soit 276252 paramètres à optimiser au total.


Laisser un commentaire